L’écosystème des modèles de langage (LLM) évolue à une vitesse impressionnante. Chaque mois, de nouveaux modèles apparaissent, qu’ils soient propriétaires ou open-source, avec des promesses de performances toujours plus élevées. Face à cette abondance, une question revient sans cesse : quel est le meilleur LLM ?
Pendant longtemps, la réponse s’est appuyée sur des benchmarks techniques standardisés. Mais ces tests montrent rapidement leurs limites lorsqu’il s’agit d’évaluer un modèle dans des conditions d’utilisation réelles. C’est précisément pour répondre à ce problème qu’est née LMArena, aussi connue sous le nom de Chatbot Arena.
LMArena, c’est quoi ?
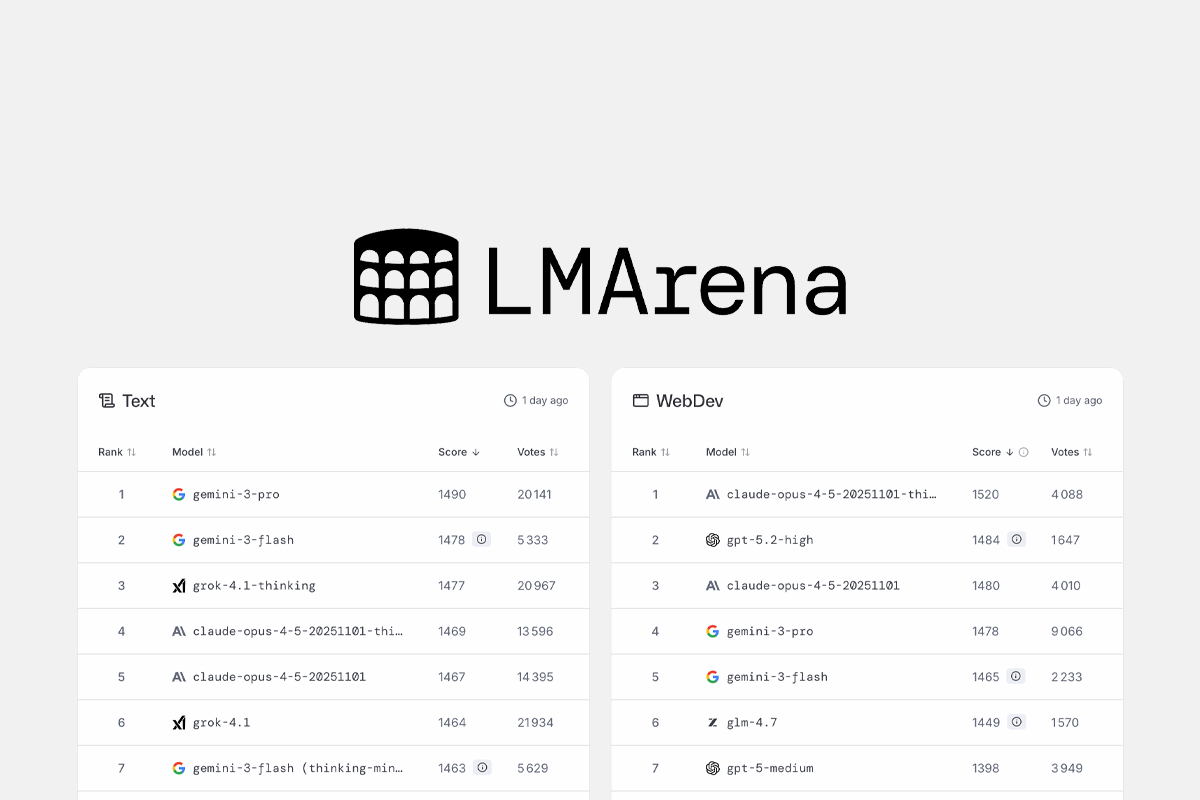
LMArena est une plateforme communautaire qui vise à comparer les modèles de langage non pas à travers des tests théoriques, mais à partir de leurs réponses réelles à des prompts humains. Son objectif n’est pas de mesurer uniquement la justesse mathématique ou la capacité à résoudre un exercice précis, mais d’évaluer la qualité perçue des réponses produites par les LLM.
Concrètement, LMArena permet à des utilisateurs de poser une question, puis de comparer deux réponses générées par deux modèles différents, sans savoir lesquels sont utilisés. L’utilisateur choisit simplement la réponse qu’il juge la meilleure. Ces votes sont ensuite agrégés pour produire un classement dynamique.

Une méthode de comparaison basée sur des duels à l’aveugle
Le fonctionnement de LMArena repose sur un principe simple mais puissant : la comparaison directe. À chaque interaction, deux modèles sont sélectionnés et soumis au même prompt. Les réponses sont affichées côte à côte, sans aucune indication sur l’identité des modèles.
Cette approche élimine volontairement le biais de notoriété. L’utilisateur ne sait pas s’il compare un modèle d’OpenAI, d’Anthropic, de Google ou un modèle open-source. Seule la qualité de la réponse compte. Ce mécanisme permet de révéler des performances parfois inattendues, notamment pour des modèles moins connus mais très efficaces dans certains contextes.
Le système de score Elo appliqué aux LLM
Pour transformer ces votes en classement exploitable, LMArena utilise un système inspiré du score Elo, bien connu dans le monde des échecs. Chaque modèle dispose d’un score qui évolue en fonction de ses “victoires” ou “défaites” lors des duels.
Lorsqu’un modèle bat un autre modèle mieux classé, il gagne davantage de points. À l’inverse, une défaite face à un modèle plus faible entraîne une perte plus importante. Ce système permet d’obtenir un classement vivant et évolutif, qui s’ajuste en permanence à mesure que de nouveaux votes sont enregistrés.

Pourquoi LMArena se distingue des benchmarks traditionnels
Les benchmarks classiques comme MMLU, GSM8K ou HumanEval sont utiles pour mesurer des capacités spécifiques, mais ils reposent sur des jeux de données figés. Les modèles peuvent alors être optimisés pour réussir ces tests sans forcément être meilleurs dans un usage réel.
LMArena adopte une approche radicalement différente. Les prompts sont variés, parfois ambigus, souvent créatifs, et surtout imprévisibles. Ils reflètent la manière dont les utilisateurs interagissent réellement avec un LLM. L’évaluation porte donc davantage sur la clarté, la pertinence, la structure des réponses et la compréhension des consignes que sur une simple exactitude académique.
Un classement orienté usages réels
Ce qui rend LMArena particulièrement intéressant, c’est qu’il met en lumière des qualités souvent invisibles dans les benchmarks techniques. Les votes des utilisateurs tiennent compte de critères implicites comme la fluidité du langage, la capacité à raisonner étape par étape, la créativité ou encore la robustesse face à des consignes mal formulées.
Ainsi, un modèle très performant en raisonnement logique peut être jugé moins convaincant en rédaction, tandis qu’un autre, plus expressif, sera préféré pour des tâches créatives. LMArena ne cherche pas à désigner un modèle parfait, mais à refléter l’expérience réelle des utilisateurs.
Avant décision

Après décision

Pourquoi le “meilleur LLM” dépend toujours de l’usage
L’un des enseignements majeurs de LMArena est qu’il n’existe pas de modèle universellement supérieur dans tous les cas. Un LLM performant pour l’écriture créative ne sera pas nécessairement le plus efficace pour le code ou l’analyse logique. De même, certains modèles excellent dans des réponses longues et structurées, tandis que d’autres brillent par leur concision.
LMArena met en évidence cette réalité en montrant que les classements peuvent varier selon les types de prompts soumis par la communauté. Cela incite à choisir un modèle en fonction du besoin, plutôt que de se fier uniquement à un classement global.

À qui s’adresse réellement LMArena ?
LMArena est utile à un large éventail de profils. Les développeurs et ingénieurs IA peuvent s’en servir pour comparer des modèles avant une intégration dans un produit. Les créateurs de SaaS et les équipes produit y trouvent un outil précieux pour orienter leurs choix technologiques. Les freelances, agences et utilisateurs avancés peuvent également y découvrir des modèles mieux adaptés à leurs usages quotidiens.
Plus largement, LMArena s’adresse à toute personne souhaitant comprendre comment les LLM se comportent dans des conditions réelles, au-delà des discours marketing.
LMArena comme outil d’aide à la décision
Plutôt qu’un simple classement, LMArena doit être vu comme un outil d’aide à la décision. Il permet d’observer les tendances, de suivre l’évolution rapide des modèles et d’identifier ceux qui offrent la meilleure expérience selon différents contextes d’utilisation.
Utilisé en complément d’autres indicateurs techniques, LMArena aide à construire des choix plus éclairés, notamment lorsqu’il s’agit de sélectionner un modèle pour une application concrète, un agent IA ou un workflow automatisé.

Limites et points de vigilance
Comme tout système basé sur des votes humains, LMArena n’est pas exempt de biais. Les préférences personnelles, l’effet de nouveauté ou le type de prompts les plus fréquemment utilisés peuvent influencer les résultats. De plus, le classement reste global et ne reflète pas toujours des besoins métiers très spécifiques.
Il est donc important d’interpréter les scores comme des indicateurs, et non comme des vérités absolues. LMArena complète les benchmarks traditionnels, mais ne les remplace pas entièrement.
LMArena s’impose aujourd’hui comme l’un des outils les plus pertinents pour évaluer les modèles de langage à travers le prisme de l’usage réel. En s’appuyant sur des comparaisons à l’aveugle et un système de score dynamique, il offre une vision plus nuancée et plus humaine des performances des LLM.
Plutôt que de chercher un vain “meilleur modèle”, LMArena invite à une réflexion plus mature : choisir le bon LLM pour le bon usage. Dans un écosystème en constante évolution, cette approche pragmatique en fait un véritable baromètre de la qualité perçue des intelligences artificielles conversationnelles.