Avec la démocratisation de l’intelligence artificielle générative, de plus en plus de développeurs et d’utilisateurs souhaitent exécuter des modèles de langage directement sur leur machine. Grâce à des outils comme Ollama, LM Studio ou encore llama.cpp, il est désormais possible de faire tourner des LLM en local sans dépendre d’un service cloud.
Mais une question revient très souvent : mon ordinateur est-il capable de faire tourner ce modèle ?
Tous les modèles d’IA n’ont pas les mêmes besoins en mémoire et en puissance de calcul. Télécharger un modèle trop lourd peut rapidement saturer la RAM ou la VRAM, rendant l’expérience inutilisable.
C’est précisément pour répondre à ce problème que l’outil Can I Run AI a été créé. Il permet d’analyser votre matériel et d’estimer quels modèles d’IA votre machine peut réellement exécuter et à quelle vitesse.
Dans cet article, nous allons voir comment fonctionne cet outil, comment interpréter ses scores et comment déterminer quels LLM sont réellement adaptés à votre configuration.
Can I Run AI : un outil pour tester la compatibilité des LLM
Can I Run AI est un outil en ligne qui permet d’évaluer la capacité de votre machine à exécuter différents modèles d’intelligence artificielle en local.
Son fonctionnement est relativement simple : l’outil analyse votre configuration matérielle et la compare aux besoins des principaux modèles disponibles. Il prend notamment en compte :
le CPU
le GPU
la VRAM
la RAM
la Bande passante mémoire
À partir de ces informations, l’outil calcule une estimation des performances pour chaque modèle et détermine si celui-ci pourra fonctionner correctement sur votre machine.
L’objectif n’est pas seulement de savoir si un modèle peut techniquement démarrer, mais surtout de savoir s’il sera réellement utilisable dans des conditions normales.

La Tier-List : voir immédiatement quels modèles tournent sur votre machine
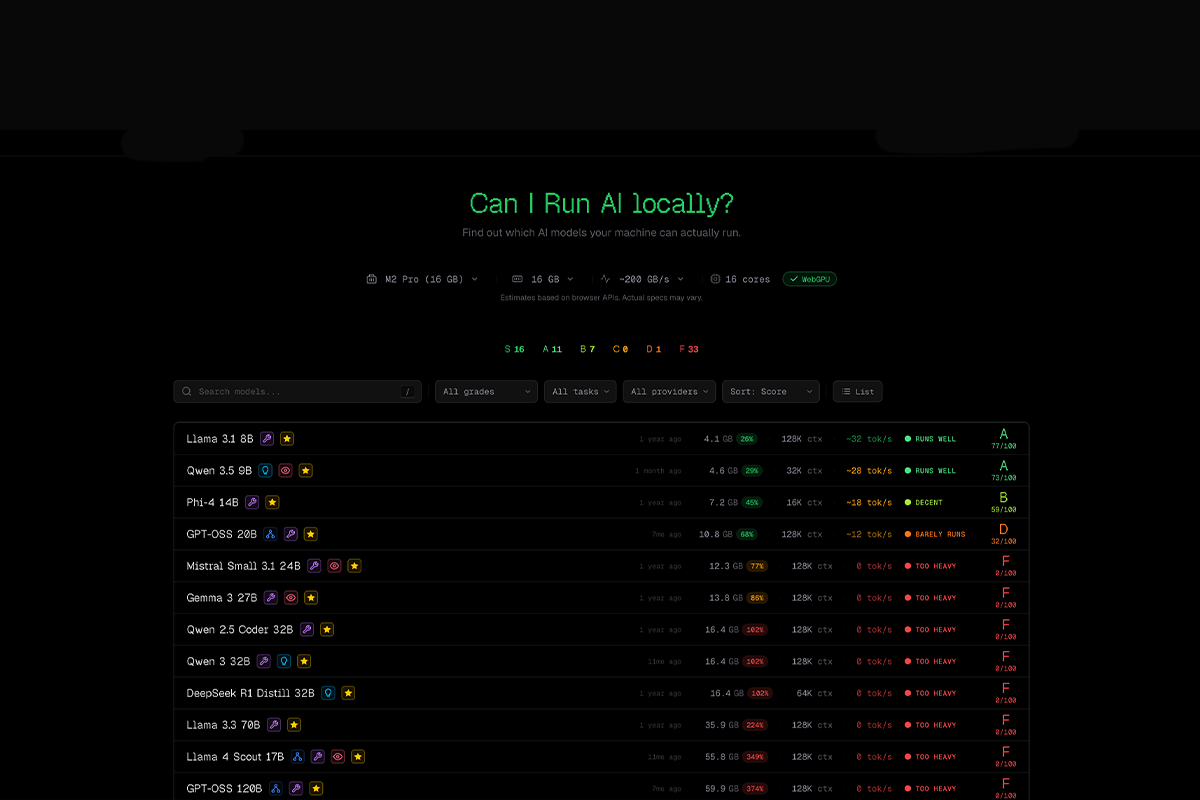
L’une des fonctionnalités les plus intéressantes de Can I Run AI est la tier list automatique des modèles compatibles avec votre configuration.
Cette liste classe les modèles selon leur capacité à fonctionner correctement sur votre matériel.
Les modèles sont répartis en plusieurs catégories :
S → Fonctionnement optimal
A → Très bonnes performances
B → Utilisable mais moins rapide
C → Limite de performance
D → Très lent
F → Trop lourd pour votre machine

Ce système permet de visualiser immédiatement quels modèles valent la peine d’être testés et lesquels sont trop gourmands pour votre configuration.
Par exemple, sur une machine équipée d’un processeur Apple Silicon avec 16 GB de mémoire unifiée, certains modèles comme Llama 3 8B ou Qwen 9B peuvent fonctionner correctement, tandis que des modèles beaucoup plus volumineux comme Llama 70B ou DeepSeek seront tout simplement trop lourds.
Cette tier list permet donc d’éviter de télécharger des modèles incompatibles et d’identifier rapidement les options les plus adaptées.
Comprendre l’échelle de score des modèles
En complément de la tier list, Can I Run AI attribue également une note globale à chaque modèle.
Cette note permet de comprendre dans quelle mesure le modèle fonctionnera correctement sur votre machine.
Voici comment interpréter ces scores :
S (85-100) → Fonctionnement excellent, très rapide
A (70-84) → Très bonne expérience
B (55-69) → Correct mais pas idéal
C (40-54) → Performances limitées
D (20-39) → Très lent
F (0-19) → Modèle trop lourd pour votre matériel

Ce système permet d’aller plus loin qu’une simple compatibilité technique. Il permet d’évaluer la qualité réelle de l’expérience utilisateur.
Un modèle qui obtient une note C ou D peut techniquement fonctionner, mais il risque d’être trop lent pour un usage quotidien.
Comment l’outil détermine si un modèle peut tourner
Avant même de calculer un score de performance, Can I Run AI vérifie si le modèle peut tenir dans la mémoire disponible.
Trois situations peuvent se produire :
CAN RUN
Le modèle utilise suffisamment peu de mémoire pour fonctionner confortablement sur votre machine.
TIGHT
Le modèle tient dans la mémoire disponible mais utilise presque toutes les ressources. Les performances peuvent être limitées.
CAN’T RUN
Le modèle dépasse la mémoire disponible. Il ne pourra tout simplement pas être chargé.

L’outil prend également en compte la différence entre deux architectures matérielles :
les machines Apple Silicon, qui utilisent une mémoire unifiée partagée entre CPU et GPU
les PC équipés d’un GPU avec VRAM dédiée
Cette distinction est importante car elle influence fortement la quantité de mémoire réellement utilisable par le modèle.
L’algorithme utilisé pour estimer les performances
Can I Run AI utilise un algorithme qui combine plusieurs facteurs pour estimer la performance d’un modèle sur votre machine. Le score final repose principalement sur trois éléments.

La vitesse d’inférence
La vitesse d’inférence correspond au nombre de tokens générés par seconde.
Plus ce nombre est élevé, plus les réponses du modèle seront rapides.
Voici quelques repères :
80+ tokens/s → très rapide
40 tokens/s → rapide
20 tokens/s → correct
10 tokens/s → utilisable
moins de 5 tokens/s → très lent
Cette vitesse dépend fortement de la bande passante mémoire et de la taille du modèle.
La mémoire disponible
La quantité de mémoire disponible détermine :
la taille maximale du modèle pouvant être chargé
la taille de la fenêtre de contexte
la stabilité du système
Un modèle qui utilise toute la mémoire disponible risque de ralentir fortement le système.
Le bonus de qualité
Certains modèles bénéficient également d’un bonus de qualité basé sur leurs performances générales et leur efficacité.
Certains modèles sont par exemple mieux optimisés pour certaines architectures ou offrent un meilleur rapport performance / taille.
L’IA locale connaît une croissance rapide, et de plus en plus d’utilisateurs souhaitent exécuter des modèles directement sur leur machine.
Cependant, tous les modèles ne sont pas adaptés à toutes les configurations. Télécharger un modèle trop lourd peut rapidement conduire à une expérience lente ou inutilisable.
C’est précisément là que Can I Run AI devient particulièrement utile. En analysant votre matériel et en estimant les performances des modèles, cet outil permet de savoir quel LLM votre machine peut réellement exécuter efficacement.
Que vous soyez développeur, chercheur ou simplement curieux d’expérimenter l’IA locale, cet outil constitue un excellent point de départ pour choisir le modèle le plus adapté à votre configuration.